複習一下昨天學到的東西,我們要先處理資料跟訓練模型,是為了讓它學會從數據中識別模式,在面對新數據時能做出準確的預測,而今天要提到的主要是關於測試集評估。
測試集評估是什麼?
它是檢驗訓練好的模型在未見過的數據上表現的過程,用來幫助我們了解模型在新數據上的表現,從而確定模型是否適合實際應用。訓練開始之前,通常會將數據集分為三個集,第一個是訓練集,用於訓練模型,第二個是驗證集,用於調整超參數,最後一個測試集則用於最終評估,進行評估後記錄模型在測試集上的表現指標。
它有一些評估指標:
1.準確率(Accuracy):正確分類的樣本數佔總樣本數的比例。
2.精確率(Precision)和召回率(Recall):特別在類別不平衡的情況下,這兩個指標更有作用。
3.F1-score:精確率和召回率的調和平均數。
4.混淆矩陣:可視化模型的預測結果,了解模型在不同類別上的表現。
測試集評估:
test_loss, test_accuracy = model.evaluate(x_test, y_test)
print(f'Test loss: {test_loss}')
print(f'Test accuracy: {test_accuracy}')
加上前面訓練後的程式碼,會得到: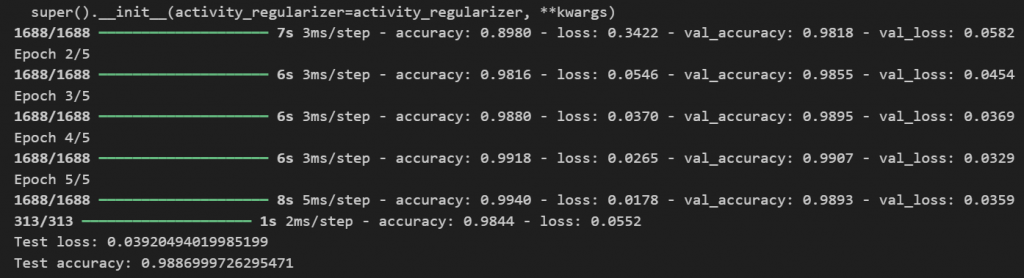
最後兩排,Test loss: 0.03920494019985199 和Test accuracy: 0.9886999726295471。
第一個是測試損失(Test loss),它的值為 0.039,表示模型的預測誤差較小,範圍越低代表模型越準確。
第二個是測試準確率(Test accuracy),約為 98.87%,代表著模型在測試集上正確分類了近 99% 的樣本,顯示模型的性能很好,能有效識別手寫數字。


 iThome鐵人賽
iThome鐵人賽